


AI Is Part of Biology's Future
It's as simple as that, and as complicated.


On April 10, 1964, the piano phenomenon Glenn Gould played his last concert. This is historic because, at the ripe age of 31 (he had played professionally since age 14), he quit public performances to commit his career to recording. All of the money in that era must have been in concerts, especially for classical musicians, so it surely looked like madness to voluntarily leave the biggest concert halls for tiny recording studios. With respect to his commitment to the studio life, Glenn said the following about recording music:
It’s the future for music:
it’s the future of performing of music,
it’s the future of writing music,
it’s the future of listening to music.
All of our futures in music are involved with recording.
It’s as simple as that, and as complicated.
Glenn Gould turned out to be very right. He was so correct that we take for granted that we live in the exact musical futures Gould described, and his vision sounds obvious now.
If a standout talent like Glenn Gould were to say this same passage above in 2022, what domains or trends might that person be referring to? It could be a biologist talking about how we understand and engineer biology in the early years of AI:
It’s the future for life sciences:
it’s the future of doing experiments,
it’s the future of analyzing experiments,
it’s the future of conceptualizing new experiments.
All of our futures in biology are involved with AI.
It’s as simple as that, and as complicated.
Hyperbolic statement or not, the bits-to-atoms interface is accelerating. I'd like to explore three major developments that I’ve observed that seem to be converging. We could visualize the three trends in a rough hierarchy:
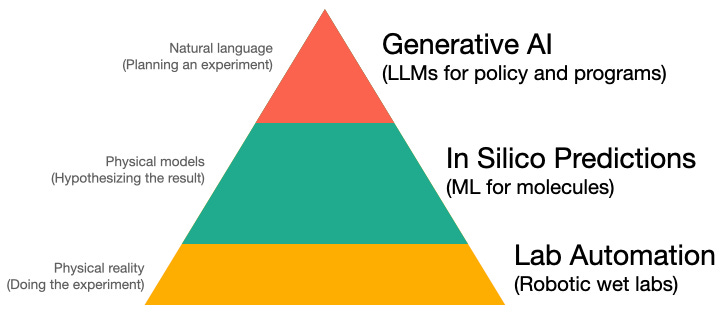
I’ll briefly explain each element independently before going into their intersections:
Generative AI is the blanket term for large, general purpose neural networks (costing millions of dollars in just compute time to train) that are now publicly usable. Large Language Models (LLMs), exemplified by GPT-3, have surpassed a threshold of capability which takes humanity into a new era of software. Specifically, the field of program synthesis (“code that writes code”) is a powerful new frontier that is in early stages of industrial deployment in computer programming but may soon have deployment applications in other fields.
In silico predictions describes molecular modeling efforts that had previously been intractable or relatively stagnant, but have recently have undergone leaps of progress1. Exemplified by the protein folding work of Google’s AlphaFold (200 Million protein structures) and Meta’s ESM (600 Million protein structures), in silico predictions have translated from basic science to drugs currently in clinical trials. Innovations for problems like reaction prediction, docking estimation and inventing molecules of arbitrary 3D shape are driving a new wave of startup formation.
Lab automation are exemplified today by cloud labs, which are a core piece of the inevitable automation coming to biology. In direct reference to the cloud compute services like AWS, cloud labs centralize CapEx-intensive robotic and wet lab resources to expose a programmatic interface for customers. Led by Emerald Cloud Lab, cloud labs are creating publicly-accessible automated services that convert bits to atoms. The thought leadership of BioAutomation, led by Erika DeBenedictis, is catalyzing the researcher community’s adoption of cloud labs in academia and early stage efforts.
What are trajectories we can observe today?
Until there are sizable incentives to do otherwise, cloud labs will continue to prioritize large contracts, likely working on high-margin, low-volume biologics in the context of human medicine2. Today, high upfront cost in terms of time and money on both the provider and customer side hinder broader adoption of general purpose cloud labs. This is why the BioAutomation Challenge is so important: it plays an essential role in accelerating cloud lab adoption in leading biology labs by (1) solving economic hurdles and (2) supporting the production of the first examples of public cloud lab source code. Thanks to Erika et al, I expect us to see dozens to hundreds of protocols in the years ahead, which could catalyze a culture shift that encourages protocol sharing.
In silico predictions are being used to today to seed libraries of molecules into automated pipelines and will continue to grow in adoption within the medical and agricultural industries. These industrial efforts and technologies will be overwhelmingly focused on the constrained problems involving a single protein (eg, antibodies, Cas-like programmable tools, drugging a target, etc.) with known biology3. The deployment will be a human determining the specifications for the software to solve, then CROs, robots or in-house scientists doing the experiments, and finally a human making judgement calls on what candidates to keep or discard. Individual companies may iterate on their processes to be more AI-powered, but I expect those improvements to be bespoke and private until a major software platform breakthrough.
Generative AI is entering a period of high growth of startups deploying foundation models. Sequoia Capital has a good overview of the first wave of growth in the expected areas of B2B services (eg, customer support replacement), graphical design (eg, product advertisements) and, perhaps most powerfully, programming (eg, CoPilot powered by Codex). Program Synthesis, “code that writes code,” is an area of computer science that went from purely academic to suddenly mainstream: Google published utilizing LLMs to program (Austin et al 2021), and Microsoft demonstrated the ability of an AI to write code to given only a unit test to pass (Haluptzok et al 2022). In addition, two other important things are emerging from LLMs:
Implicit Knowledge rather than Explicit Knowledge Graphs: Computer Science leaders like Jure Lescovec (eg, SMORE paper 2022) have done pioneering work in creating knowledge graphs from various sources of information. What is surprising to many who explore the giant black boxes of LLMs is that it appears there is some sort of knowledge graph that links concepts stored inside the model from training, but we do not yet know how to formalize it or study it. Prompt engineering, led by Riley Goodside and others, seems to be the best approach at the moment.
Demonstration of mathematical knowledge being represented and manipulated with LLMs: Google’s Minerva project showed the quantitative reasoning ability of language models by ingesting 118GB of data from Arxiv into a pre-trained PaLM model. Similarly, autoformalization is the process of converting natural language mathematics into a formal structure and is now being done with LLMs. And recently a multi-company, multi-institute collaboration made an even more powerful theorem proving approach called Draft, Sketch and Prove. This work shows the ability of the latest neural networks to formalize natural language technical content and to apply (what looks like?) first-principles reasoning.
Given all the activity recently, I offer three theses for discussion:
Thesis 1: The creation of knowledge models may be more important than automation source code examples. Synthace is already building software to abstract the user from the fine details of lab automation code. For human-human knowledge transmission, publicly available cloud lab source code or protocols is essential for reproducing and building upon other’s results. But for an AI agent to determine specifications for a given engineering task, the agent will likely be traversing knowledge in some explicit or latent space and could output results in a formalized language that would be trivial to put into a cloud lab. GPT-3 has been demonstrated to already have capabilities for step-by-step logic and knowledge querying. This thesis could be explored today by seeing how much extra work on top of an existing foundation model is needed for GPT-3 to give instructions on how to do a PCR covid tests in a lab setting.
Thesis 2: Somebody is going to ingest all 100TB of SciHub into a Foundation Model, it’s just a matter of who, when and what (if any) the subsequent legal ramifications will be. GPT-3 was mostly trained on web crawling and books, so only 3% of the training weight was wikipedia in 2020 (6 million articles, 50 million other pages of content, 3 billion tokens, average of 584 words per article). For reference, SciBERT was trained on 1.14MM papers from SemanticScholar which has 3 billion tokens. SciHub has 88MM papers, and if we assume that we can extrapolate the Semantic Scholar dataset statistics (2600 words per article) with some paper loss due to old/faulty PDFs, it could be reasonable to expect 200+ billion tokens of scientific knowledge, roughly 10x bigger than the Minerva training set of Arxiv papers (21 billion tokens). For reference, this is almost half as big as the total training data that went into GPT-3. This is a 10x boost in technical knowledge that would exist inside current LLMs. It looks like DeepForest is engaged in the effort to make molecular foundation models and I’m looking forward to seeing what they create. When somebody does create this Ultimate Science Foundation Model (brand name pending…), and it may have already been done, I expect there to be a surprisingly powerful knowledge graph baked in that could take people years to explore. It is essential that such a trained model become a public good.
Thesis 3: There will be a universal language of physical science work that does not speak directly to humans. Monolithic cloud labs alone may not be optimal deployment of automated biology in the future. Projects like PyHamilton demonstrate growing open source communities for benchtop automation, and the SayCan collaboration by Google and Everyday Robots is a reminder of how multifunctional robots are steadily progressing (as well as ultralight indoor drones). As the cost curve goes down and the natural-language programmability goes up, there may be an intersection at which it is easier to convert an existing lab environment/protocol into an automated one, rather than to outsource work to a physically separate facility. Or, there may be a steady-state solution that some tasks are optimal for large automated warehouses and others are optimized for more distributed, edge labs. If there is any future of multiple robotic work providers, then interoperability will become a bottleneck, which will motivate a universal formalization of life science work.
Personally, I’m most excited to see how AI can help us navigate enormous wells of scientific knowledge (eg, our geochemical negative emissions technologies review) to propose and execute experiments that expand the frontiers of planetary-scale biotechnology. I think it’s important to get high-impact problems into the discussion that may not obvious short-term payoffs: medical applications are well-defined and financially mature4, whereas frontiers of energy, food and biological resilience are critical but under-resourced relative to impact. New AI abilities might change the calculations of costs/risks to make new spaces suddenly tractable: for example, ML protein engineering tools today are powerful but multi-protein complexes (eg, the exquisite nitrogen splitting anvil) have been out of reach. The next generation of computational tools, if properly integrated into experimental workflows, could help us operate at the horizons that Stephen Hawking saw in 2000:
I think the next century will be the century of complexity. We have already discovered the basic laws that govern matter and understand all the normal situations. We don't know how the laws fit together, and what happens under extreme conditions. But I expect we will find a complete unified theory sometime this century. That will be the end of basic theory. But there is no limit to the complexity that we can build using those basic laws. This complexity can be biological or electronic.
—Stephen Hawking in an interview, San Jose Mercury News, January 23, 2000.
To conclude on an emotional note: this is a phase change moment in time, the future is uncertain and only getting harder to predict. This is uncomfortable for many. It doesn’t help that the vast majority of our SciFi universes skew deeply negative (shoutout to the solarpunks and those trying to build positive outlooks), so let me leave you with the mental image of Glenn Gould back at his piano. He is older now, in the small room he chose over the palatial concert hall, in an environment he meticulously crafted to the degree of individual baffle positions5, surrounded by the best recording engineers in the business who had passed his quizzes. Glenn is sitting exactly 14 inches off the ground on the only chair he ever played on, hunched over a piano that is on wooden blocks to get his precise desired height. He is in his moment of flow born of decades of mastery dedicated to getting the perfect sound of Bach out from the piano and stored onto tape. And in this moment, Glenn Gould is singing his heart out.

Acknowledgements:
There are many amazing people I’ve discussed these ideas with over the past two weeks, and I hope you know I’m very appreciative of our conversations. Specific thanks to Matt B, Jacob A, Tom K, Erika D, Neiman M, Jose L, Paul R, Jake F, James K, and Eitan M.
Experimentalists will emphasize that these predicted structures are not perfectly “solved” and these protein models very greatly in quality. Even so, I think most would agree that the utility and availability of these estimates has created a big change in parts of the biosciences.
It is very likely the cloud labs are servicing agricultural clients, but from my experience, AgTech is currently much more opaque (ie, publishes less) than human medicine.
Drug delivery is another large area of focus due to obvious financial benefits.
The space of “AI + Drug Discovery” has been growing for a decade+ with companies like In Sitro, Recursion, Generate, etc…
This is a fun album of outtakes and interviews with the sound engineers who worked with Glenn Gould.
Congrats on putting together some cool concrete proposals on how near-term AI can accelerate science. Usually ideas are much more vague.
Some comments:
1. Scihub hosting PDFs (instead of .doc or txt) may present a challenge to one of your proposals, depending how difficult high-quality OCR turns out to be and how sensitive LLM learning is to minor spelling/typographic errors. Captions in figures can matter a lot sometimes.
2. Automated labs seem sketchy from a security standpoint. Hope we can have some oversight to make sure people don't make bioweapons in their backyard. On the other hand, maybe they're safer, to the degree this leads to centralization over decentralized labs.